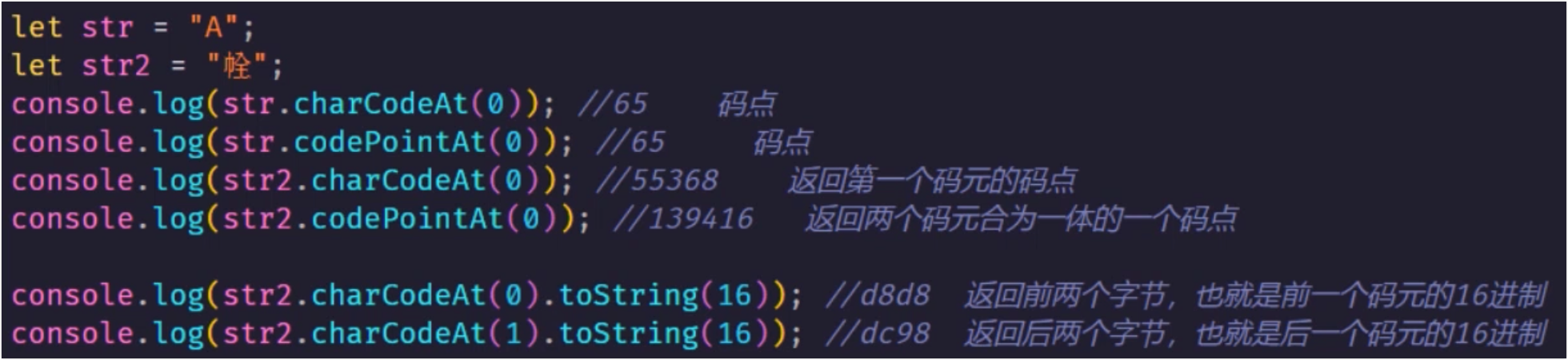
码点
某个字符规定对应的数值
// 根据字符获取码点
const str = 'a'
console.log(str.codePointAt()) // 97
// 根据码点获取字符
console.log(String.fromCodePoint(97)) // a码元
Javascript 字符串的 length 属性返回的是 码元
对于 UTF-16 来说,一个码元是 16bit(两个字节)
对于 UTF-32 来说,一个码元是 32bit(四个字节)
JavaScript 内部,字符以 UTF-16(字符用两个字节或四个字节表示的格式储存)
- 码点范围介于
0-65535的字符,两个字节 - Unicode 码点大于
65535的字符,四个字节
- 码点范围介于
codePointAt与charCodeAt接受的索引值都是根据码元codePointAt函数匹配规则是码点,当它匹配到当前索引的码元后会识别当前的码元是否和后面的码元能否构成一个码点,如果是 一个码点,则返回这两个码元的码点,如果不能构成一个码点,就按照当前的码元返回码点ES6 考虑到了这个问题,其原型上实现了
Symbol.iterator,使得其可以使用for of来遍历其值
ASCLL 码
美国标准信息交换代码啊
- ASCII 码占用一个字节,一个字节为 8 个 bit 位
- ASCI 码第一位始终是 0,那么实际可以表示的状态是 2^7=128 种字符
- EASCLL 码,为了适应更多字符(128-255),不常用
码表
| ASCII 值 | 控制字符 | ASCII 值 | 控制字符 | ASCII 值 | 控制字符 | ASCII 值 | 控制字符 |
|---|---|---|---|---|---|---|---|
| 0 | NUL | 32 | (space) | 64 | @ | 96 | 、 |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | ” | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | ' | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | h |
| 9 | HT | 41 | ) | 73 | I | 105 | i |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | - | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DCI | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | TB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | \ | 124 | | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ~ |
| 31 | US | 63 | ? | 95 | — | 127 | DEL |
说明
0-31 为控制字符;32-126 为打印字符;127 为 Delete(删除)命令
| 十进制 | 十六进制 | 字符 | 十进制 | 十六进制 | 字符 |
|---|---|---|---|---|---|
| 0 | 00 | 空 | 16 | 10 | 数据链路转意 |
| 1 | 01 | 头标开始 | 17 | 11 | 设备控制 1 |
| 2 | 02 | 正文开始 | 18 | 12 | 设备控制 2 |
| 3 | 03 | 正文结束 | 19 | 13 | 设备控制 3 |
| 4 | 04 | 传输结束 | 20 | 14 | 设备控制 4 |
| 5 | 05 | 查询 | 21 | 15 | 反确认 |
| 6 | 06 | 确认 | 22 | 16 | 同步空闲 |
| 7 | 07 | 震铃 | 23 | 17 | 传输块结束 |
| 8 | 08 | backspace | 24 | 18 | 取消 |
| 9 | 09 | 水平制表符 | 25 | 19 | 媒体结束 |
| 10 | 0A | 换行/新行 | 26 | 1A | 替换 |
| 11 | 0B | 竖直制表符 | 27 | 1B | 转意 |
| 12 | 0C | 换页/新页 | 28 | 1C | 文件分隔符 |
| 13 | 0D | 回车 | 29 | 1D | 组分隔符 |
| 14 | 0E | 移出 | 30 | 1E | 记录分隔符 |
| 15 | 0F | 移入 | 31 | 1F | 单元分隔符 |
Unicode 码
又称统一码、万国码,为世界上所有字符都分配了一个唯一的编号(码点),并没有规定存储方式
- 编号范围(十六进制)从
0x000000到0x10FFFF,有 100 多万(1114112)个 - 每个字符都有一个唯一的 Unicode 编号
- Unicode 是字符集,为了兼容 ASCIL,规定
0-127个字符是和 ASCIl 是一样的,不一样的是128-255这一部分
字符表示方式
\
\转义字符,是一个特殊的存在大多数情况下,不产生什么作用,只对一些特殊的字符起作用
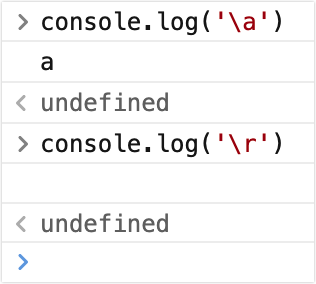
### \ 八进制
表示码点范围值为 0-255,有些特殊码点的字符不能被正常显示
模板字符串中不能直接使用,需要使用单引号包裹
${字符'\56'}
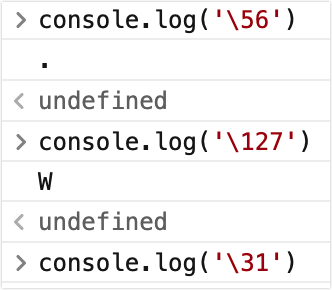
\x 两位十六进制
表示码点范围值为 0-255,有些特殊码点的字符不能被正常显示
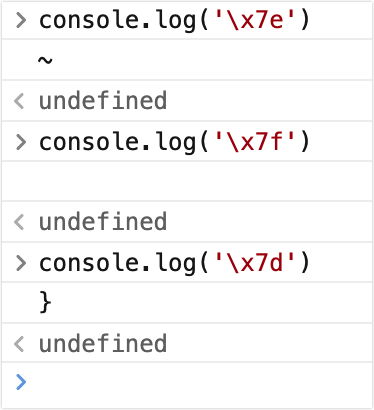
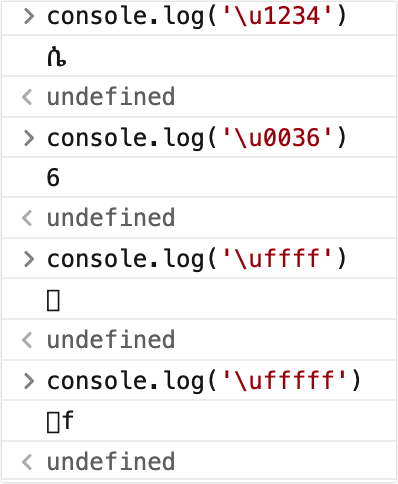
\u 四位十六进制
表示码点范围值为 0-65535,固定 4 位十六进制
少于四位时会报语法错误
多余四位时,多余字符原样输出
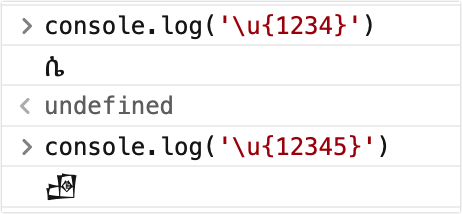
\u {十六进制}
ES6 新增能力,可以表示超出 65535 范围的字符
在 CSS 中可以不写 u 和大括号,例如
a::before{ content: '\1234';}
字符实际应用
- 正则匹配常用中文
- 去掉空白字符
- 等等...
UTF-8/UTF-16
均是 Unicode 编码的一种实现,定义了编码在计算机中的存储方式
UTF-8 是互联网使用最多的一种 Unicode 的实现方式
- 变长的编码方式(1-4 个字节)
JavaScript 代码中的字符和 localStrage 存储的字符是基于 UTF-16 编码的
cookie 存储的字符是基于 UTF-8 编码的
UTF-16 缺点
- 空间浪费,最低单元采用了两个字节
- 目前 Unicode5.0 收录的字符已经超过了 UTF-16 所能表达的最大范围
Base64
说明
Base64 编码后的数据都是 ASCll 字符
早期邮件传输协议基于 ASCII 文本,对于诸如图片、视频等二进制文件处理并不好。ASCII 主要用于显示现代英文,到目前为业只定义了 128 个字符,包含控制字符和可显示字符为了解决上述问题,Base64 编码顺势而生。 Base64 是编解码,主要的作用不在于安全性,而在于让内容能在各个网关间无错的传输,这才是 Base64 编码的核心作用。
组成
64 表示编码后的字符由 64 种字符排列组合而成
还有一个字符
=(最多出现两次),是填充字符,不属于 64 里面的范畴
- A-Z(26)
- a-z(26)
- 0-9(10)
+、/(2)
优缺点
优点
- 可以将二进制数据(比如图片)转化为可打印字符,方便传输数据
- 对数据进行简单的加密,肉眼是安全的
- 如果是在 html 或者 css 处理图片,可以减少 http 请求
缺点
- 内容编码后体积变大,至少 1/3,因为是三字节变成四个字节,当只有一个字节的时候,也至少会变成三个字节
- 编码和解码需要额外工作量
应用
Canvas 图片生成
canvas 的 toDataURL 方法可以把 canvas 画布内容转成 base64 编码格式包含图片展示的 data URI
const ctx = canvasEl.getContext('2d')
// other code ...
const dataUrl = canvasEl.toDataURL()
// dataUrl输出结果 data:image/png;base64, iVBORw0KGgoAAAANSUhE...文件获取
FileReader 的 readAsDataURL 方法可以把上传的文件转为 base64 格式的 data URI,比较常见的场景是用户头像的剪裁和上传
<input type="file" id="inputFile" />
<button onclick="previewImg()">预览图片</button>
<br /><br />
<img src="" id="avatar" alt="预览图" />
<script>
function readAsDataURL() {
const fileEl = document.getElementById('inputFile')
return new Promise((resolve, reject) => {
const reader = new FileReader()
const curFile = fileEl.files[0]
reader.readAsDataURL(curFile)
reader.onload = function () {
resolve(reader.result)
}
reader.onerror = reject
})
}
function previewImg() {
readAsDataURL().then(res => {
const el = document.getElementById(id)
el.setAttribute('src', dataSrc)
})
}
</script>JWT
JSON Web Token:前后端安全校验机制
- 由
header、payload、signature三部分组成 header和payload解码后,是明文看见的
图片优化
直接用 base64 编码之后的字符代替小图片
减少一次请求,浏览器默认请求网站图标 favicon.ico,替换为最小图片字符之后可以节约一次网络请求
<link rel="icon" href="data:," />
<Link rel="icon" href="data:;base64,="最小图片字符计算由来
<canvas height="0" width="0" id="canvas"></canvas>
<script>
const canvasEL = document.getElementById('canvas')
const ctx = canvasEl.getContext('2d')
dataUrl = canvasEl.toDataURL()
console.log(dataUrl) // data:,
</script>SourceMap
SourceMap 中的 Mappings 字段使用 Base64 编码的,不可直接解码
混淆加密代码
著名的代码混淆库
javascript-obfuscator中有 base64 的应用,webpack-obfuscator也是基于其封装的
其他
X.509、GitHub SSH Key、mht 文件、邮件附件等等